Modele językowe nazywane bardzo wyniośle „AI” rozeszły się po sieci lepiej niż niejeden wirus. Niektóre służą do generowania grafiki, inne tworzą dla nas muzykę a jeszcze inne klipy wideo. Najpopularniejsze jednak wykorzystywane są jako generatory tekstów, które symulują rozmowę z pewną formą inteligencji. Nie da się ukryć, że odpowiedzi różnych modeli językowych są dość dobre i osoba niewtajemniczona mogłaby pomyśleć, że po drugiej stronie siedzi człowiek. ChatBoty pomagają nam na co dzień odpowiadając na zapytania z najróżniejszych dziedzin. Czasami jednak chciałoby się zadać pytanie zawierające wrażliwe dane, a modele językowe jak wiemy są obecnie kontrolowane przez duże korporacje, które uwielbiają zbierać dane. Pojawił się jednak sposób na to, aby taki model językowy uruchomić lokalnie, na własnym komputerze, nawet bez dostępu do internetu!
Projekt GPT4ALL
Narzędzie GPT4ALL zostało opublikowane z inicjatywy firmy Nomic AI. Open-source’owy charakter oprogramowania sprawia, że nie ma ono konkretnego twórcy, jest to wspólne dzieło wielu programistów, którzy udzielali się przy projekcie. Sam projekt ma na celu sprawienie, aby model językowe były dostępne dla każdego, bez ograniczeń. Z mojej perspektywy idealnie wpisuje się to w ramy pracy z systemami Linux i ogólną misją szerzenia wolnego oprogramowania.
Samo narzędzie dostępne jest na wszystkie platformy, zarówno komercyjne jak i niekomercyjne. Nas interesuje wersja przeznaczona dla Linuxów. Projekt dostępny jest do pobrania jako paczka .deb, czyli typowy instalator dla systemów opartych o Debiana / Ubuntu, oraz do zainstalowania przez Flatpak. Sprawia to, że z GPT4ALL można korzystać na prawie każdej dystrybucji. W trakcie testów będę pracował z Ubuntu 24.04 zainstalowanym na maszynie wirtualnej, ale całą instalację przeprowadzę właśnie z poziomu menedżera Flatpak.
Dostępne modele językowe
Zanim jednak przejdziemy do instalacji warto wspomnieć, że GPT4ALL w przeciwieństwie do wszystkich modeli językowych potrafi pracować w trybie offline. Wymaga to oczywiście połączenia z siecią w trakcie instalacji, ale po pobraniu programu oraz wybranej biblioteki możemy odłączyć sieć i pracować w pełni w trybie offline. Sprawia to, że wszystkie nasze pytania przetwarzane są lokalnie i nie wędrują nigdzie w formie jakichkolwiek pakietów danych o użytkowniku i jego zapytaniach.

Obecnie dostępne są modele Llama 3 (opracowany przez Meta), Nous Hermes 2, Mistral Instruct, ChatGPT 3.5 oraz ChatGPT 4 (ChatGPT w obu wariantach potrzebuje klucza API). Wspomniane modele są pobierane w całości (jako zestaw instrukcji) i nawet w chwili utraty dostępu do sieci radzą sobie całkiem dobrze z przetwarzaniem wprowadzonych danych i generowaniem odpowiedzi. Pewnie maja swoje limity, chociaż mi osobiście na kilkudziesięciu pytaniach testowych nie udało się nie uzyskać odpowiedzi.
Instalacja GPT4ALL
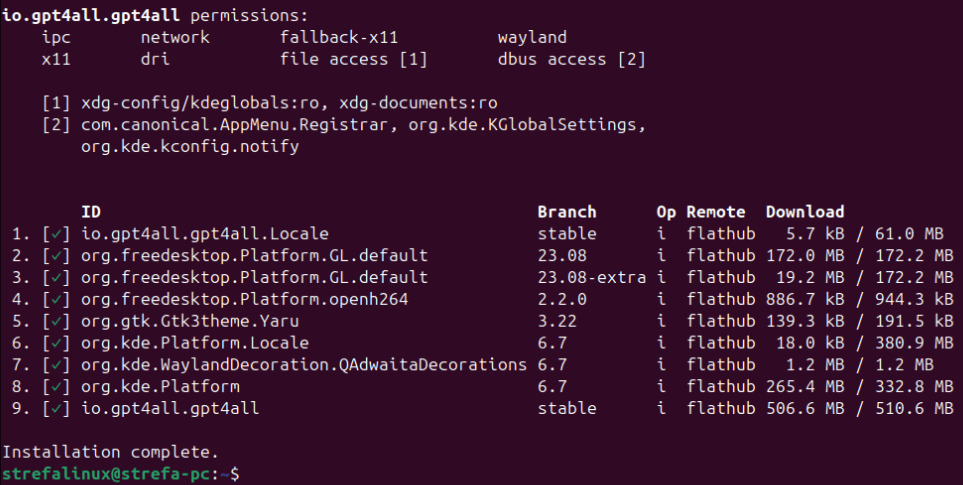
Instalację w systemie Ubuntu 24.04 przeprowadzę z użyciem menedżera instalacji pakietów Flatpak oraz repozytorium Flathub. Jeśli nie posiadasz w swoim systemie Flatpaka to zachęcam do zapoznania się z moim poradnikiem dotyczącym instalacji i konfiguracji menedżera Flatpak. Po zainstalowaniu menedżera i dodaniu repozytorium możemy przejść do instalacji. Pierwszy krok to wpisanie polecenia:
flatpak install flathub io.gpt4all.gpt4all

Po wyświetleniu zapytania o to, czy chcemy wprowadzić zmiany i zainstalować pakiety potwierdzamy wpisując dwukrotnie „Y” i zatwierdzając Enterem. Całość wymaga pobrania około 500MB, więc trzeba chwilę odczekać.
Dla pewności, że wszystkie biblioteki wczytają się poprawnie dobrze jest uruchomić ponownie system (polecenie reboot w terminalu). Po ponownym uruchomieniu wśród zainstalowanych w systemie aplikacji powinien pojawić się także GPT4ALL.

Instalacja wybranej biblioteki
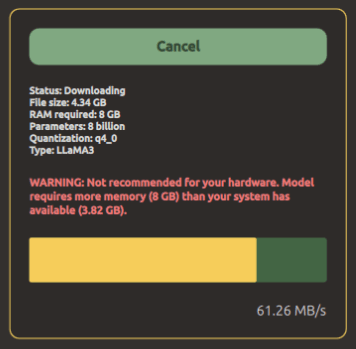
Po pierwszym uruchomieniu program zapyta, czy chcemy wysyłać anonimowe statystyki. Tutaj wybór zostawiam Wam, w zależności od tego gdzie, jak i po co pracujecie z modelami językowymi. Kolejny krok to pobranie jednego z dostępnych modeli językowych. Na początek polecam Llamę 3 od Mety – bardzo dobrze pracuje nawet po odcięciu się od sieci. W tym celu należy kliknąć przycisk „Download” przy pozycji „Llama 3 Instruct„.

Plik zajmuje trochę ponad 4 GB, więc trzeba uzbroić się w cierpliwość. Na szczęście po pobraniu program jest praktycznie gotowy do pracy.
Praca z programem
Zanim rozpoczniemy wpisywanie pytań i „rozmowę” z modelem językowym należy w górnej części głównego okna wybrać model, z którym chcemy pracować. Jeśli pobierzemy więcej modeli niż jeden wszystkie będą widoczne tutaj w formie rozwijanej listy.

Następnym krokiem jest utworzenie nowego chatu poprzez kliknięcie przycisku „+ New chat” po lewej stronie ekranu.

Nie pozostaje nic innego jak rozpoczęcie wpisywania zapytań w dolnej części ekranu (w polu „Send a message…„).
Oczywiście nie mogło być inaczej i pierwsze pytanie jakie zadałem dotyczyło Linusa Torvaldsa, twórcy Linuxowego jądra. Przez pracę na maszynie wirtualnej, która posiada jedynie 4 GB RAM-u i dwa rdzenie CPU praca programu była dość powolna, ale po kilku minutach miałem wygenerowaną gotową odpowiedź. Całość oczywiście w języku angielskim. Llama radzi sobie dobrze z odczytywaniem języka polskiego, ale nie potrafi wygenerować odpowiedzi w tym języku.
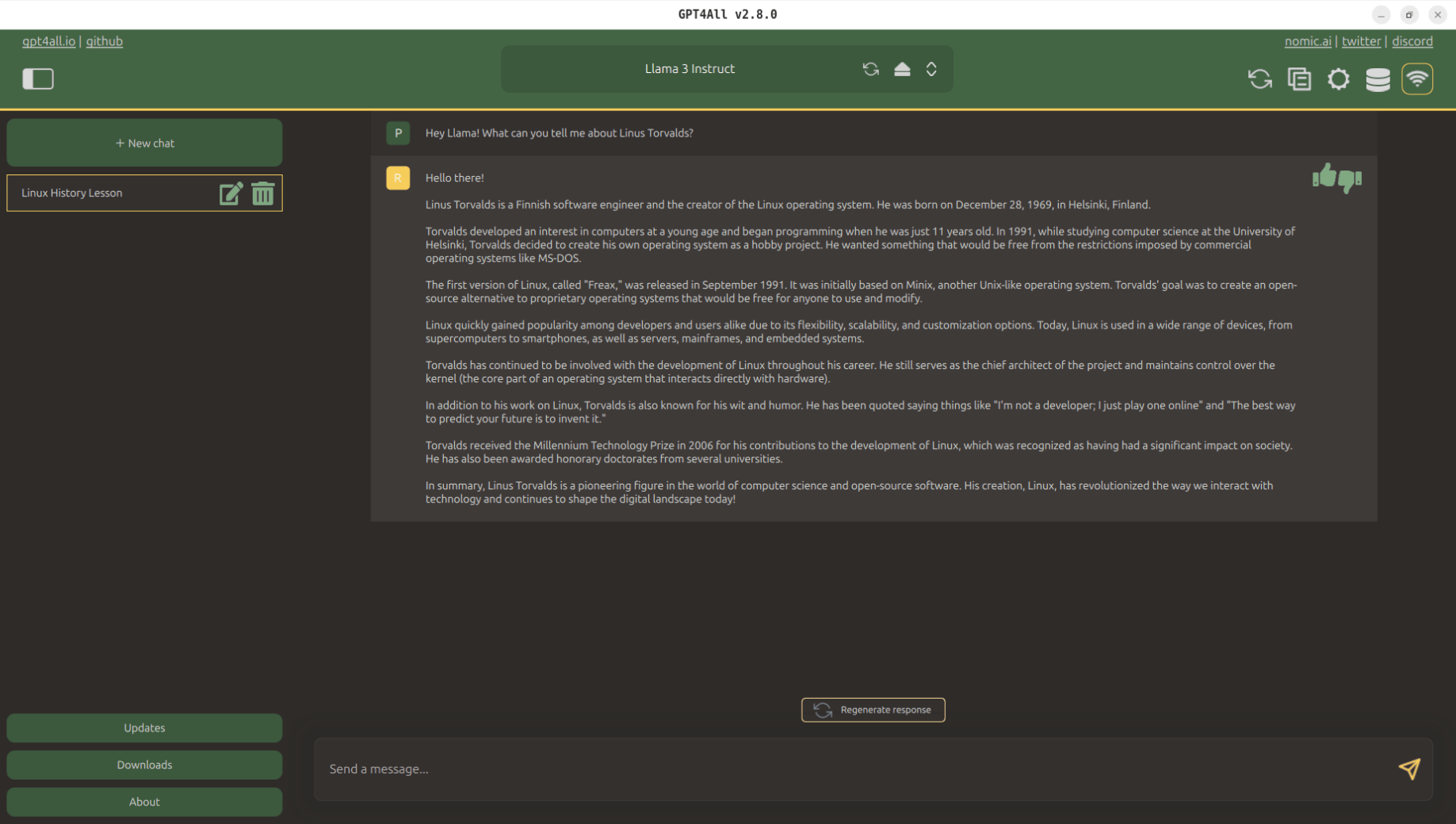
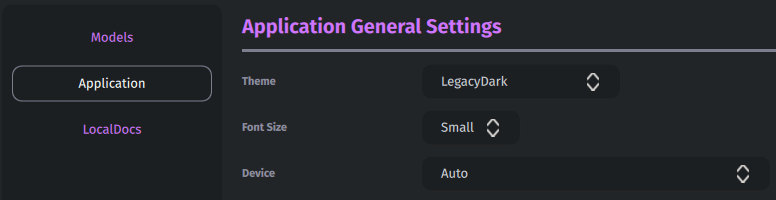
Do pracy z modelami językowymi lokalnie polecam co najmniej 16 GB pamięci RAM i jak najświeższy procesor z 6-8 rdzeniami. Wtedy odpowiedzi są generowane praktycznie w czasie rzeczywistym. Gdybym miał podpowiedzieć coś jeszcze to byłaby to informacja o możliwości zmiany kolorów okna. Po wejściu w Ustawienia (ikona zębatki w prawym górnym rogu), a następnie w zakładkę „Application” z rozwijanej listy w pozycji „Theme” można wybrać opcję „LegacyDark„. Program przyjmuje wtedy przyjemniejsze, fioletowe barwy. Oczywiście jest to kwestia indywidualna, ale w moim przypadku ten motyw zdecydowanie mniej męczy oczy.
Podsumowanie
Gdybym miał podsumować pracę z programem powiedziałbym, że jeśli ktoś korzystał z narzędzi od OpenAI (np. ChatGPT), to cały układ programu będzie mu dobrze znany. Obsługa jest bardzo prosta, intuicyjna i przede wszystkim – bezpieczna. Wystarczy odpiąć kabelek od sieci i nasze pytania zostaną tylko i wyłącznie na naszym komputerze. Osobiście na pewno skorzystam z narzędzia nie raz, bo podczas nauki różnych języków programowania modele językowe potrafią być świetną inspiracją (np. weryfikacja kodu czy wymyślanie przykładowych projektów pozwalających na wykorzystanie zgromadzonej wiedzy). A jak to wygląda u Was? Skorzystacie z narzędzia, czy raczej unikacie modeli językowych nazywanych szumnie Sztuczną Inteligencją? Czekam na opinie w komentarzach.



Zaskoczyłeś mnie, nie spodziewałem się, że można odpalić GPT lokalnie. 4 GB i czas generowania odpowiedzi robią wrażenie, ale mimo wszystko rewelka. Ciekawe jak by to szybko szło na sprawniejszej maszynie.
Nie ukrywam, że sam byłem mocno zaskoczony za pierwszym razem. Tak potężne narzędzie na tak słabej wirtualce a i tak dawał radę. Testowałem też na swoim głównym pececie – 6 rdzeniowy Core i5, 16 GB RAM, GTX 1650 – czas odpowiedzi praktycznie tak szybki, jakbym odpalił ChatGPT przez przeglądarkę. Myślę, że przy 32 GB RAM-u nie byłoby już żadnej różnicy.